Résumé
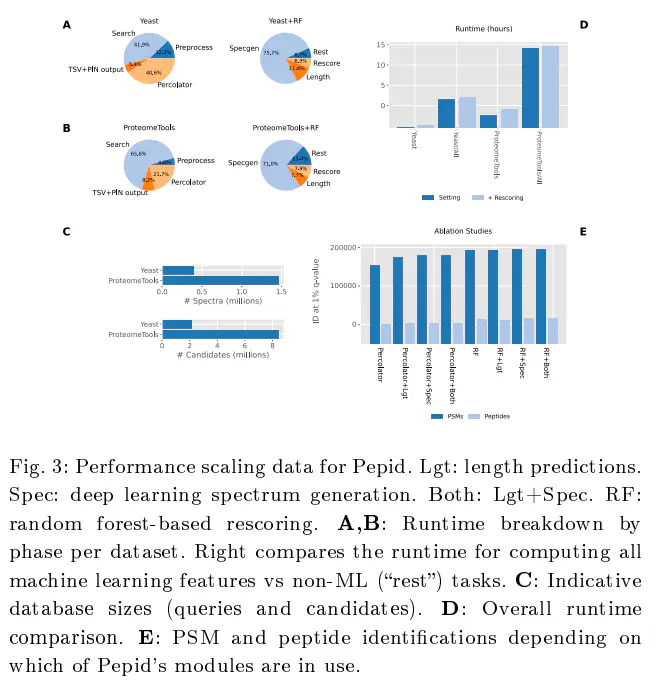
Motivation Current peptide search engines are optimized for wet-lab work ows, i.e. they operate in an endto-end manner to achieve good identi cation results, not to be modi ed or provide algorithmic insight. This makes developing new software methods to solve problems in peptide identi cation methods di cult, often requiring a full engine rewrite. Recently, many deep learning methods were proposed as solutions to various parts of the peptide identi cation task, but virtually none of those methods have been implemented in any actual peptide search process. We believe that the lack of a reliable bioinformatics research platform for peptide identi cation that enables such integrations is slowing down proteomics research as a whole.,
Jérémie Zumer
Étudiant au doctorat en informatique
Étudiant au Doctorat en Informatique | Amélioration de la spectrométrie de masse peptidique par l’apprentissage profond
Sébastien Lemieux
Chercheur principal
Chercheur principal, Unité de recherche en bio-informatique fonctionnelle et structurale, IRIC | Direction scientifique de la plateforme de Bio-informatique | Professeur agrégé, Département de biochimie et médecine moléculaire, Université de Montréal