Utilisation de l'IA pour l’apprentissage de représentations RNA-Seq en transcriptomique
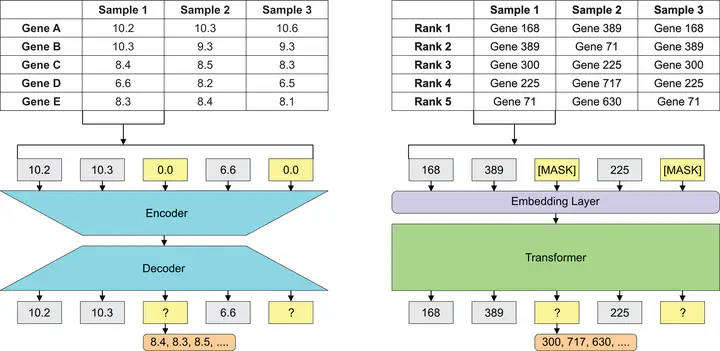
Les représentations vectorielles des gènes (gene embeddings) exploitent de vastes ensembles de données RNA-seq en capturant les patrons de co-expression, permettant ainsi aux réseaux neuronaux profonds (DNN) de caractériser numériquement les fonctions géniques et les rôles régulateurs. Ces modèles sont fortement sensibles à la manière dont les données de séquençage de l’ARN sont encodées, laquelle peut varier entre des valeurs d’expression brutes traditionnelles et des approches fondées sur le classement (ranking), inspirées des word embeddings en traitement automatique du langage naturel.
Ce projet étudie comment les représentations d’entrée et les méthodes de tokenisation interagissent avec différentes architectures de réseaux neuronaux, ainsi que leur impact sur l’inférence biologique.
Les résultats préliminaires montrent des performances similaires pour la prédiction des lignées cellulaires, tandis que les embeddings basés sur les valeurs brutes surpassent les embeddings fondés sur le classement lors du préentraînement masqué, avec des erreurs plus importantes pour les gènes de rang intermédiaire. Les travaux en cours évalueront des tâches aval supplémentaires et exploreront des architectures hybrides intégrant les deux types de représentations, dans le but de capter des caractéristiques transcriptomiques complémentaires et d’améliorer la précision des prédictions à travers différentes tâches.